
Mit zunehmender Reife nutzen agile Teams Metriken, um ihren kontinuierlichen Verbesserungsprozess zu gestalten. Gerade für Kanban-Teams ist die Lead Time, also die Durchlaufzeit von Arbeitspaketen, dabei ein wichtiger Kandidat.
Letztes fragte eine Entwicklerin bei einem Kunden in die Runde: „Ok, unsere Lead Time ist 18 Tage… ist das jetzt gut? Oder schlecht?“ Sie wünschte sich Hilfe bei der Interpretation der Metriken. Der Agile Coach gibt natürlich nicht einfach eine Antwort, sondern stellt eine Gegenfrage: „Du meinst den Durchschnitt, schätze ich. Was ist besser? Ein Lead-Time-Durchschnitt von 18 Tagen oder von 14 Tagen?“
Die richtige (oder zumindest bessere) Antwort ist nun leider nicht: Natürlich 14 Tage! Es ist wichtig, zu verstehen, dass Lead-Time-Angaben ohne Streumaß wenig aussagekräftig sin. Also: 14 Tage im Schnitt, ok, aber was ist bei euch der minimale und maximale Wert? Wie verteilen sich die Lead Times um den Durchschnitt herum?
Lead Times: Die Streuung machts
Bevor wir ins mathematisch-philosophische abgleiten, fragen wir zuerst noch mal: Was ist uns eigentlich wichtig? Ist es wichtig, dass wir manchmal extrem schnell liefern, aber manchmal auch extrem lange brauchen? Dann wäre ein niedrigerer Durchschnittswert der Lead Time wünschenswert, ohne Rücksicht auf Verluste (i.e. Ausreißer, die ewig dauern).
Meistens ist das aber nicht das, worum es uns geht. Meistens geht es darum, dass wir zuverlässig liefern. Dass wir also vielleicht nicht ganz so schnell liefern, aber dafür mit hoher Vorhersagbarkeit schnell genug liefern. Schauen wir ein konkretes Beispiel an.
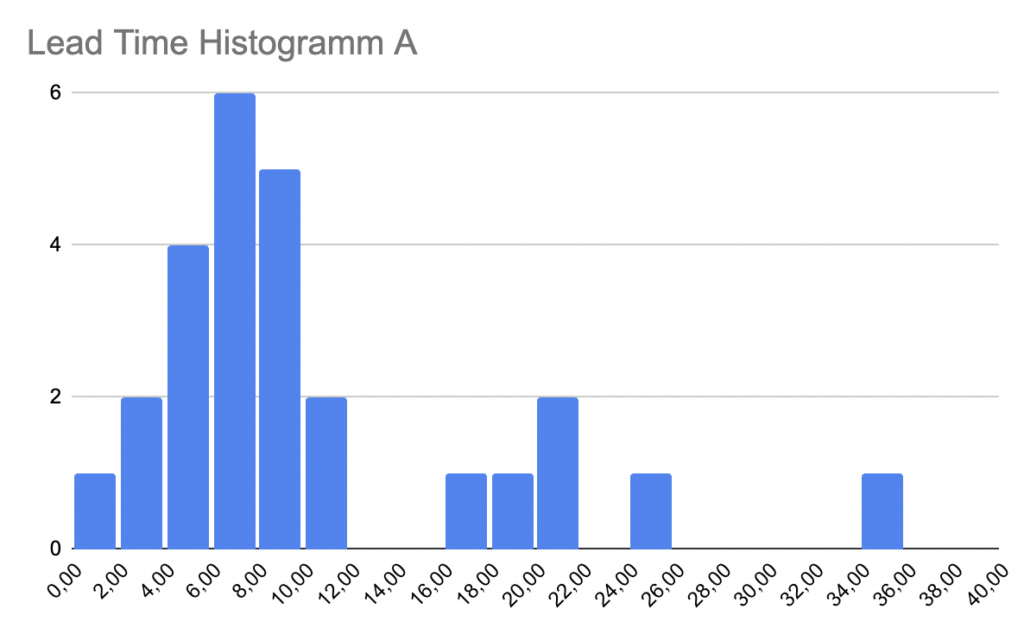
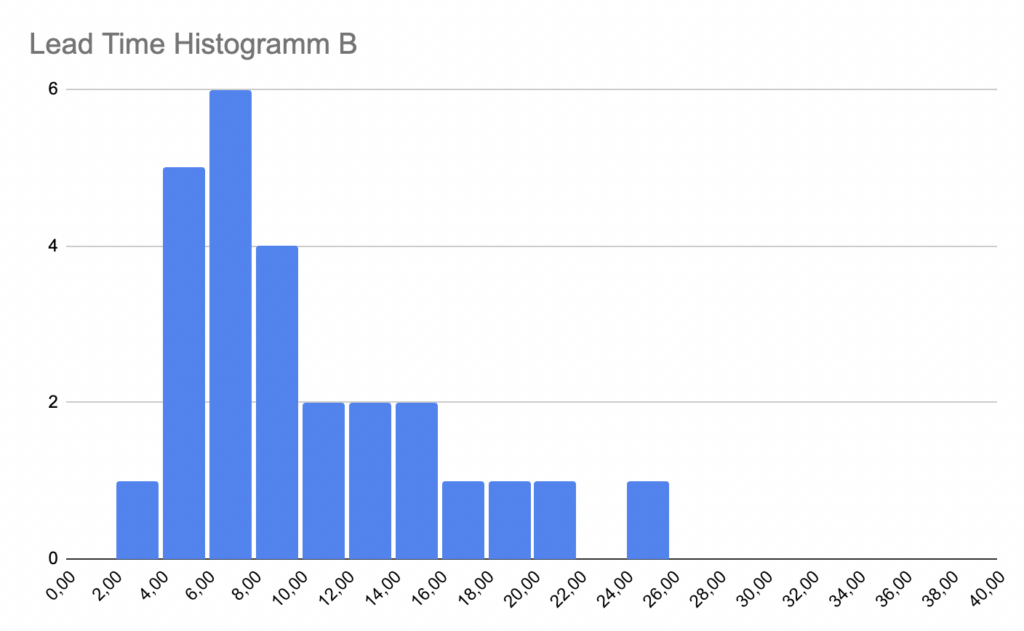
Die beiden Lead-Time-Verteilungen A und B sehen relativ ähnlich aus. Der Durchschnitt der beiden Datenmengen ist auch ähnlich, 10.04 bei A und 9.69 bei B. Die Einheit ist für unsere Zwecke hier egal, es könnten Tage sein, Wochen, Monate, es geht ja nur um den Vergleich.
Welche Lead Times sind besser, A oder B?
Welche Lead Times sind nun besser, A oder B? Wie gesagt, das kommt darauf an, was man mit besser meint. Ein zentrales Ziel von Kanban ist verbesserte Vorhersagegüte. Wenn der Kunde fragt „Wann ist es fertig?“ hilft es ja wenig, wenn man sagen kann „In 10 Tagen“, dabei aber in circa 50% der Fälle falsch liegt, länger braucht und sein Lieferversprechen somit bricht. Besser bedeutet also nicht, dass der Durchschnitt niedriger ist, sondern dass die Streuung schmaler ist, also die „Breite“ der Verteilung. Get rid of the tail ist deshalb eine wichtige Devise der Kanbanistas. Was ist der Tail? Die vielen Issues rechts in der Verteilung. Hier zwei Verteilungen, eine mit fat tail, eine mit thin tail.
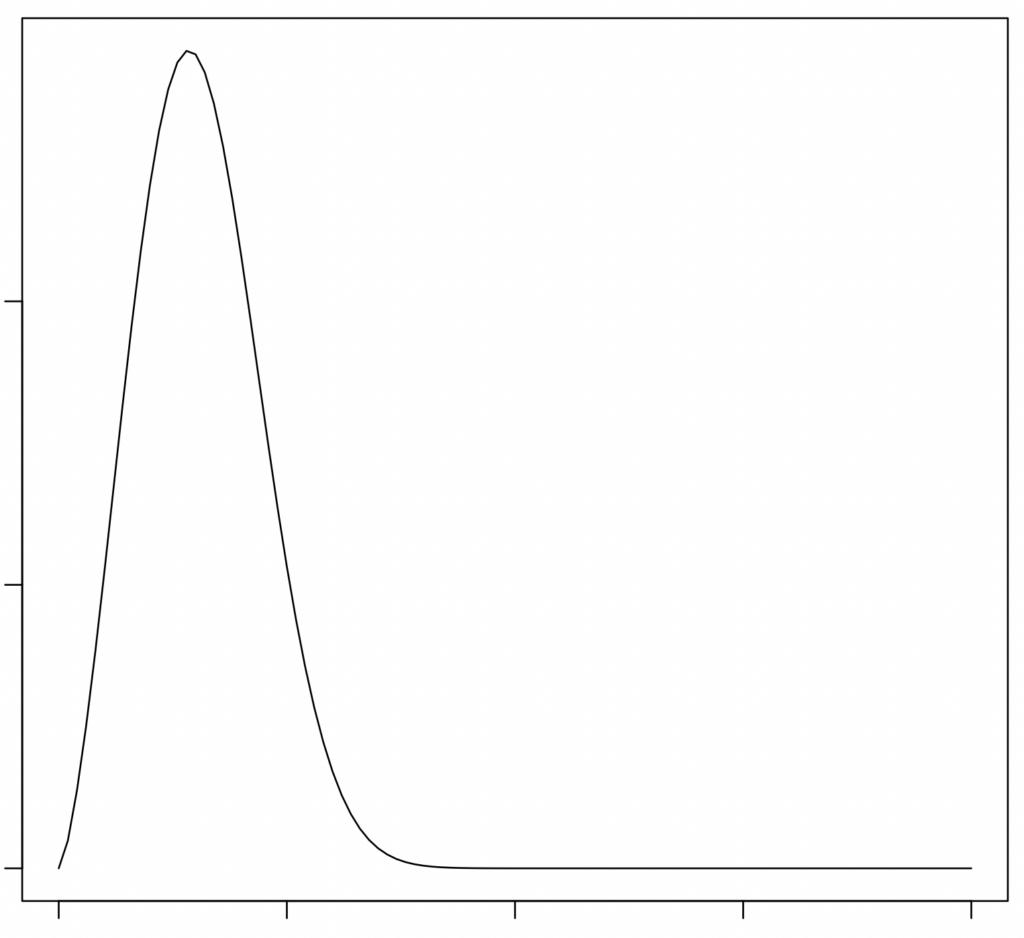
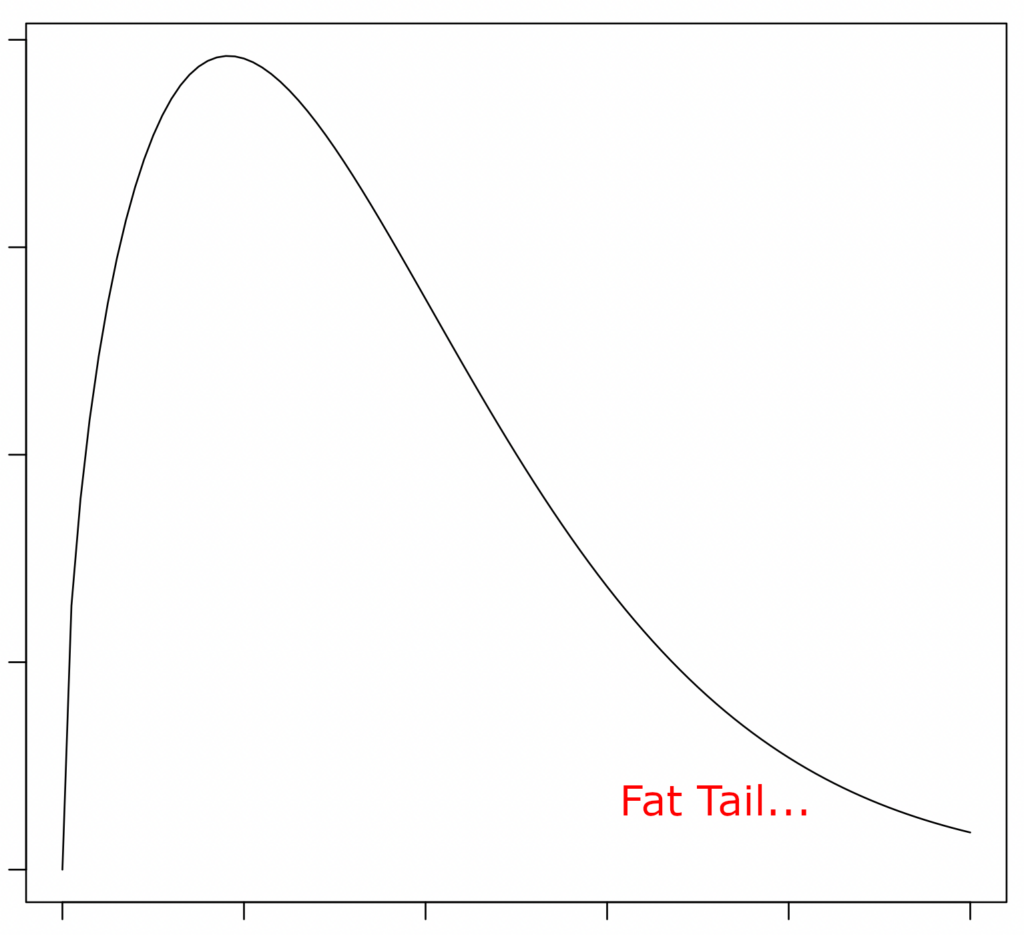
Mittelwert bringt nichts, benutzt Perzentile!
Schauen wir uns unter diesem Gesichtspunkt jetzt noch mal die o.g. Lead-Time-Verteilungen A und B an. Es ist klar geworden, dass allein der Durchschnitt keine gute Aussage ist. Wir müssen irgendwie auch was darüber sagen, wie weit nach rechts unsere Verteilung ragt. In industriellen Settings wie z.B. Fertigung wird dafür gern die sog. Standardabweichung genutzt, ein statistisches Maß, auch genannt Sigma (daher hat Six Sigma seinen Namen). Darauf wollen wir hier gar nicht eingehen, weil die Standardabweichung bei Lead-Time-Verteilungen von Arbeitspaket-Durchlaufzeiten keine gute Aussagekraft hat. Sie funktioniert optimal nur für symmetrische Verteilungen.
Wir verwenden hier besser sog. Perzentile. Sie teilen die Verteilung in zwei Teile, das 50. Perzentil zum beispiel Hälfte-Hälfte: Die eine Hälfte der Werte ist unter dem Median-Wert, die andere Hälfte über dem Median-Wert. Wenn der Median z.B. 7 ist, und ich sage „In 7 Tagen ist es fertig“, dann bin ich in der Hälfte der Fälle schneller, in der anderen langsam. Eine Fifty-Fifty-Chance ist, wie gesagt, kein guter Forecast, den ich an Kunden kommunizieren will.
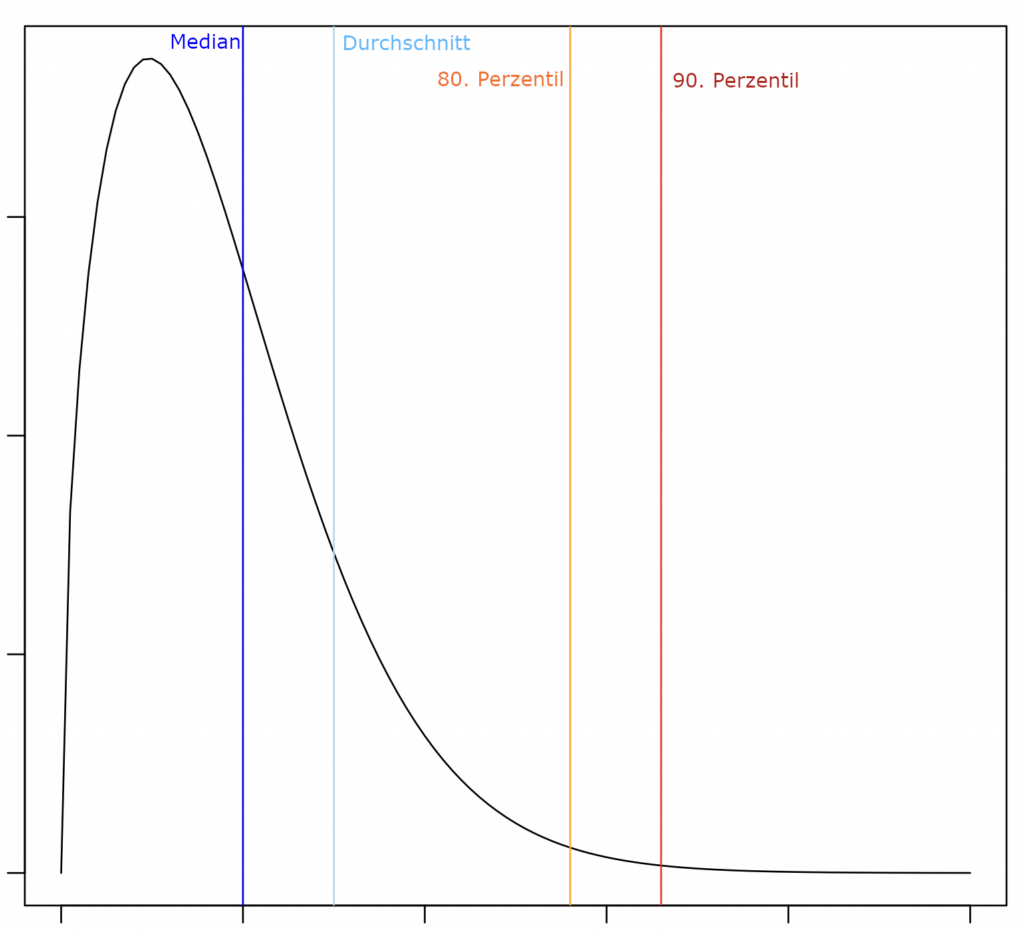
Das 80. Perzentil sagt: In 80% der Fälle brauch ich so lang oder kürzer. Das ist schon besser! Wenn das 80. Perzentil meiner Verteilung bei 15 Tage liegt, und ich sage dem Kunden „In 15 Tagen ist das Arbeitspaket fertig“, dann liege ich in 4 von 5 Fällen (80%) richtig. Wenn es heikel ist, die Abgabefrist zu überschreiten, gehe ich auf Nummer sicher und wähle das 90. Perzentil — jetzt werde ich in 9 von 10 Fällen rechtzeitig abgeben. Eine weiterführende Besprechung der Charakteristika von Lead-Time-Verteilungen findet man in den hervorragenden Artikeln auf Alexei Zheglovs Blog. Aber jetzt noch mal zu A versus B!
Noch mal: Welche Lead Times sind besser, A oder B?
Die entsprechenden Werte für die o.g. Verteilungen A und B sind:
- Mittelwert 10.04
- Median 7.5
- 80. Perzentil 17
- 90. Perzentil 20.6
Bei B sieht es so aus:
- Mittelwert 9.69
- Median 8
- 80. Perzentil 14
- 90. Perzentil 17.6
Wenn wir also sagen, Schnelligkeit im Schnitt ist nicht alles, Vorhersagegüte ist wichtig, dann ist Verteilung B besser für mich, weil die Lead Time, die ich mit sehr hoher (80% bzw. 90%) Wahrscheinlichkeit vorhersagen/versprechen kann, um drei Tage kürzer ist als bei A. Der ähnliche Mittelwert täuscht darüber hinweg, dass die Verteilung der Werte bei B kompakter und damit für die Vorhersagegüte besser ist.
Fazit: Wenn man Lead-Time-Verteilungen anschaut, ist der wichtigste Ansatz: Get rid of the tail!
Achtung: Die aus den Daten abgeleiteten Perzentilwerte sind nur Annäherungen an das, was wir statistisch erwarten können. Wir müssen eigentlich eine Monte-Carlo-Simulation über unsere Daten machen. Warum das so ist, ist z.B. in diesem Artikel beschrieben.


